✅ Put your name here
¶
Multiple-sample testing against a control group¶

Credits: xkcd.com
Learning goals for today’s pre-class assignment¶
Use Dunnett’s test for multiple samples against a control in the parametric case
Use a modified Conover’s test in the non-parametric case
Assignment instructions¶
This assignment is due by 11:59 p.m. the day before class, and should be uploaded into the appropriate “Pre-class assignments” submission folder. If you run into issues with your code, make sure to use Slack to help each other out and receive some assistance from the instructors. Submission instructions can be found at the end of the notebook.
Make all the needed imports before anything else¶
import numpy as np
import pandas as pd
from scipy import stats
from matplotlib import pyplot as plt
import scikit_posthocs as posthocsWe will make jitterplots across the assignment (and other plots), so it is good idea to define some variables from the the get-go
# Random noise for the jitterplots
rng = np.random.default_rng(seed = 42)
nudge = rng.uniform(-0.15, 0.15, 1000)
# Lists of colors and markers
colors = ["#a1dab4", "#41b6c4", "#2c7fb8", "#253494", "#ffffcc"]
markers = ['o', '^', 's', 'D', 'v']
# fontsize for all the plots
fs = 121. Kruskal-Wallis omnibus H-test: Contaminated pollen¶
(We already walked through this whole pipeline in the last pre-class, but here’s another example if you need it.)
So far we have been stating rules of thumb of what test to do based on whether the data is normal-ish or not. As a reminder, this is referred to as parametric versus non-parametric tests.
Parametric tests assume that the data follows a parametric distribution, namely a Normal distribution. A normal distribution can be defined by its two parameters: mean and standard deviation.
Non-parametric tests make no such assumption. Usually they convert the data to ranks, in a way very similar to what Spearman does when computing correlation.
In the last class we practiced using parametric omnibus and post hoc tests—ANOVAs, Tukey’s HSD, Games-Howell, and Tamhane’s . But what if our data is not normal-ish?
The Kruskal-Wallis H-test is the non-parametric equivalent of ANOVA. It poses the null hypothesis:
There is no difference among the means of the given samples.
1.1 Loading and preparing data¶
As an example, let’s look at the contaminated pollen data from Days 15 and 16. We want to know if alpine skyline flowers report more or less pollen contamination—relative amount of Salix pollen—depending on the collection site. Or phrased another way: Is there a region in Colorado that is particularly contaminated with Salix pollen?
data = pd.read_csv('2016+population+survey.csv')
print(data.shape)
data.head()(120, 7)
Let’s make a list with the contamination values, one list item per site. The single-line loop below is Python’s shorthand for:
samples = []
for site in sites:
yvals = data.loc[data['site'] == site, 'frequency of Salix pollen']
samples.append( yvals )sites = data['site'].unique()
print('List of unique sites in the data:\n', *sites, sep='; ')
# A list with all contamination values, one list entry per site
samples = [ data.loc[data['site'] == site, 'frequency of Salix pollen'] for site in sites ]List of unique sites in the data:
; Pennsylvania Mountain; Weston Pass; Hoosier Pass - East; Hoosier Pass - West
1.2 Q-Q plots and jitterplots¶
Remember: testing for normality with Q-Q plots is our bread. Visualizing our data as jitterplots alongside their mean and confidence intervals is our butter.
alpha = 0.1
quantiles = np.linspace(alpha, 1-alpha, 10)
fig, ax = plt.subplots(1, len(sites), figsize=(3*len(sites), 3))
for i in range(len(sites)):
dataq = np.quantile(samples[i], quantiles)
normq = stats.norm.ppf(quantiles, loc=samples[i].mean(), scale=samples[i].std())
ax[i].scatter(dataq, normq, c='b', ec='k')
ax[i].axline([dataq[0], dataq[0]], slope=1, c='r')
ax[i].set_title(sites[i], fontsize=fs)
fig.supxlabel('Data quantiles', fontsize=fs)
fig.supylabel('Normal quantiles', fontsize=fs)
fig.tight_layout()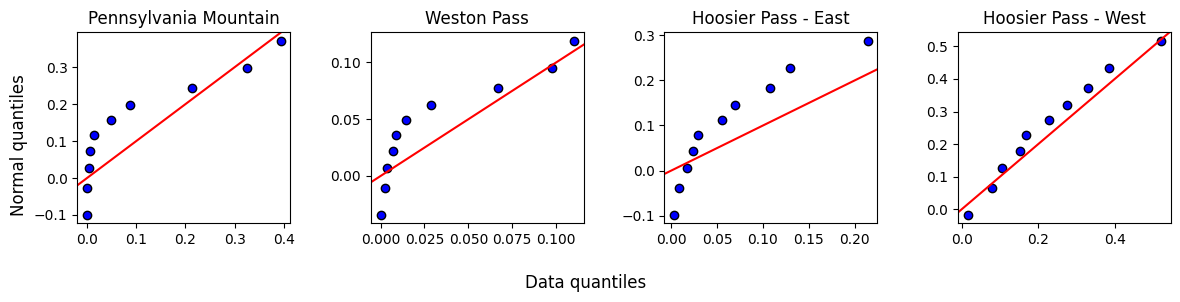
Other than Hoosier West, the data does not look normally distributed. We will need a non-parametric procedure.
Before going further, it always good to visualize the data and the 95% Confidence Intervals. That way, we will know what to expect from the post-hoc analyses.
fig, ax = plt.subplots(1, 1, figsize=(6, 4))
ax.axhline(0, c='dimgray', zorder=1)
ax.set_xticks(range(len(sites)), sites, rotation=10, va='center_baseline')
ax.tick_params(labelsize=fs)
for i in range(len(sites)):
ci = stats.t.ppf(0.975, len(samples[i])-1)*samples[i].sem()
ax.scatter(i + nudge[:len(samples[i])], samples[i], color=colors[i], marker=markers[i], ec='lightgray', lw=0.5, zorder=2)
ax.errorbar(i , samples[i].mean(), yerr=ci, color='k', mew=1.5, elinewidth=1.5, capsize=5, mfc='w', marker='D', zorder=3)
fig.supylabel('Contamination %', fontsize=fs)
fig.tight_layout()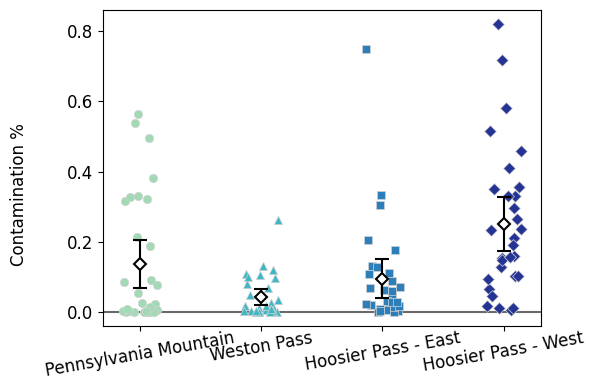
1.3 Does pollen contamination vary by site?¶
We compute a Kruskal-Wallis H-test with stats.kruskal. Similar to the stats.tukey_hsd, notice that this function needs a list with a *.
stats.kruskal(*samples)KruskalResult(statistic=26.119085363308844, pvalue=9.005233512021801e-06)Are there any significant differences?
The p-value is small, so we reject the null hypothesis. We might hypothesize that contamination does indeed vary by site.
However, Kruskal-Wallis does not tell us which sites—if any—are different from which. One crude posthoc procedure would be to compare all six possible sites with Mann-Whitney tests (because we are doing everything non-parametric) and then adjust p-values with Benjamini-Hochberg to correct for false positives.
But we can consider all samples at once for better results.
1.4 Conover’s test: non-parametric equivalent for Games-Howell¶
Unfortunately, stats does not do any non-parametric post hoc tests. The good news is that scikit_posthocs has our back.
Conover test does not adjust p-values for false positives automatically!
You have to specify that with the p_adjust parameter. We’ll do fdr_bh for the Benjamini-Hochberg procedure.
# Just like with posthoc_tamhane, we get a DataFrame as an output
# We then re-name the columns and indices so it is easier to read what p-value goes with what sites
pvalues = posthocs.posthoc_conover(samples, p_adjust='fdr_bh')
pvalues.columns = sites
pvalues.index = sites
pvaluesIt seems that Hoosier West is different from the rest of sites.
These other three sites—Pennsylvania Mountain, Weston Pass, and Hoosier East—are similar to each other.
This observations match the jitterplots.
1.5 Sidenote: scikit_posthocs works with full DataFrames as well¶
The scikit_posthocs test functions behave nicely with full DataFrames—stats test functions prefer lists, arrays, or Series.
Instead of a list of samples, we can simply give posthoc_conover our complete DataFrame and simply tell it which column has the contamination values and which column has the site values. Notice we get the same p-values as above.
# No need to fiddle around with the resulting pvalues dataframe
posthocs.posthoc_conover(data, val_col='frequency of Salix pollen', group_col='site', p_adjust='fdr_bh', sort=False)1.6 Dunn’s test: another alternative (not that different)¶
Dunn’s test is another non-parametric multiple-sample post hoc test. It is also in scikit_posthocs. It is a bit worse than Conover but not by thaaat much. Don’t lose sleep over which of these two to choose. Just be aware it exists.
# No need to fiddle around with the resulting pvalues dataframe
posthocs.posthoc_dunn(data, val_col='frequency of Salix pollen', group_col='site', p_adjust='fdr_bh', sort=False)And ultimately, our observations with Conover are the same compared to those we drew with Dunn.
1.6 Displaying statistical differences in plots¶
We have already discussed papers where letters are added to barplots/boxplots/jitterplots to indicate that these two samples are the same or different. In fact, Figure 4 from Kettenbach et al (2017) displays these letters. Good news: posthocs.compact_letter_display prints the letters for us.
We also add the
.str.strip()function to remove any trailing, extra white spaces.
cld = posthocs.compact_letter_display(pvalues).str.strip()
cldPennsylvania Mountain a
Weston Pass a
Hoosier Pass - East a
Hoosier Pass - West b
Name: letters, dtype: objectWe can incorporate them to the jitterplot we already had.
Check how the
haandvaparameters—horizontal and vertical text alignment, respectively—work here.
fig, ax = plt.subplots(1, 1, figsize=(6, 4))
ax.set_facecolor('snow')
ax.axhline(0, c='dimgray', zorder=1)
ax.set_xticks(range(len(sites)), sites, rotation=10, va='center_baseline')
ax.tick_params(labelsize=fs)
for i in range(len(sites)):
ci = stats.t.ppf(0.975, len(samples[i])-1)*samples[i].sem()
ax.scatter(i + nudge[:len(samples[i])], samples[i], color=colors[i], marker=markers[i], ec='lightgray', lw=0.5, zorder=2)
ax.errorbar(i , samples[i].mean(), yerr=ci, color='k', mew=1.5, elinewidth=1.5, capsize=5, mfc='w', marker='D', zorder=3)
# Get the max contamination value for the site, and increase it 5%
max_pol = samples[i].max()*1.05
# Print the corresponding letter on top of it
ax.text(i, max_pol, cld[sites[i]], ha='center', va='bottom', fontsize=1.1*fs)
# Extend the y-axis values so the letters remain within the plot
# First get the current y-axis limits
ylim = ax.get_ylim()
# Set the minimum to 0 (because there are no negative contamination values)
# Increase the maximum by 10%
ax.set_ylim(0, ylim[1]*1.1)
# add a grid
#ax.grid(axis='x', zorder=1)
fig.supylabel('Contamination %', fontsize=fs)
fig.tight_layout()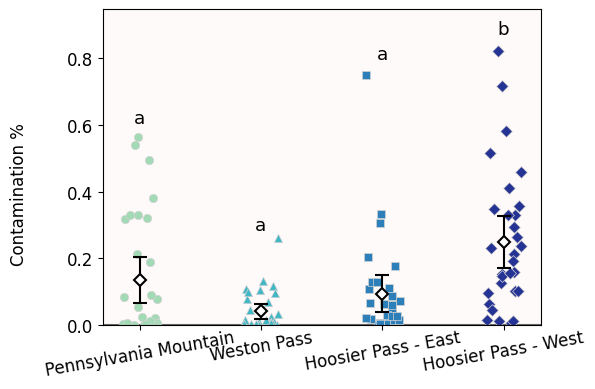
I admit that the one downside of jitterplots is that difference letters do not look as good on them compared to barplots/boxplots.
2. Multiple-sample tests with Control: restored prairies¶
So far, our multiple-sample tests compare everybody against everybody.
Sometimes, we only want to compare everybody against a common control group. For example, if we have blood pressure drugs A, B, and C, we are only interested in comparing A, B, C against control. We do not really care about comparing A versus B. In such setting, we have dedicated tests:
Parametric option: Dunnett’s test
Non-parametric option: Dunn’s test with manual p-value adjustment.
2.1 Loading and grouping data¶
For this second example we will use the seed rain and restored praire dataset you used for Homework 04.
We load the data
We group it by
Plot(prairie restoration age) and sum all the seeds found in eachTransect
data = pd.read_excel('Seed_Data_2019.xlsx')
total_seeds = data.groupby(['Plot', 'Transect'], as_index=False)['Number'].sum()
total_seeds.head()We do our usual jitterplot visualizaiton
xlabs = total_seeds['Plot'].unique()
fig, ax = plt.subplots(1,1, figsize=(4,4))
for i in range(len(xlabs)):
y = total_seeds.loc[total_seeds['Plot'] == xlabs[i], 'Number']
ci = stats.t.ppf(0.975, len(y)-1) * y.sem()
ax.scatter(i + nudge[:len(y)], y, color=colors[i], zorder=1, marker=markers[i], ec='lightgray', lw=0.5)
ax.errorbar(i , y.mean(), yerr=ci, color='k', mew=1.5, elinewidth=1.5, capsize=5, mfc='w', marker='D', zorder=3)
ax.axvline(2.5, c='gray', ls='dashed')
ax.set_facecolor('snow')
ax.set_yticks(range(0,10001,2500),range(0,10001,2500))
ax.set_xticks(range(len(xlabs)), xlabs, fontsize=fs)
ax.set_ylabel('Number of seeds', fontsize=fs)
fig.tight_layout()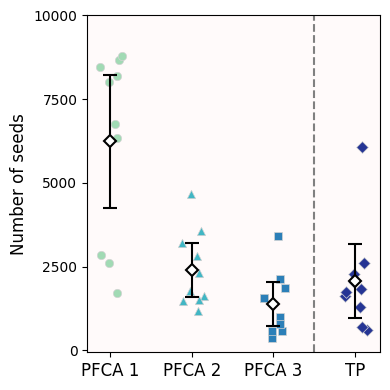
2.2 Dunnett’s test¶
In this case, all we care about is comparing restored prairies against a remnant one (control). We are not interested in comparing recently restored praires against older restored praires. And so, we use Dunnett’s test—we are assuming data is normal-ish.
Dunnett already controls for false positives, so you don’t need to further adjust.
We can use either the stats.dunnett or the posthocs_dunnett functions. The way you pass the data is different for each though. Here, we’ll use the posthoc_dunnett version because it accepts whole dataframes.
dunnett = posthocs.posthoc_dunnett(total_seeds, val_col='Number', group_col='Plot', control='TP')
dunnettNotice that the only p-values reported are those comparisons against control
The young prairies are very different from the remnant ones
The middle-aged and old prairies are not statistically different from the remnant ones
2.3 Another way to showcase significance: ***¶
Notice that Figure 1 from Wynne et al (2024) does not use letters—because it is not doing all comparisons—and instead uses * to show which samples are different to control.
We can quickly get a table of stars with the posthocs.sign_table function. As its documentation reads:
NSmeans not significant, p-value .*means p-value**means p-value***means p-value
I find a bit annoying that you cannot customize the threshold values, but you can define your own function to do this.
stars = posthocs.sign_table(dunnett)
starsAnd repeat the jitterplot, now indicating significance:
fig, ax = plt.subplots(1,1, figsize=(4,4))
for i in range(len(xlabs)):
y = total_seeds.loc[total_seeds['Plot'] == xlabs[i], 'Number']
ci = stats.t.ppf(0.975, len(y)-1) * y.sem()
ax.scatter(i + nudge[:len(y)], y, color=colors[i], zorder=1, marker=markers[i], ec='lightgray', lw=0.5)
ax.errorbar(i , y.mean(), yerr=ci, color='k', mew=1.5, elinewidth=1.5, capsize=5, mfc='w', marker='D', zorder=3)
# Get the max value and increase it by 5%
max_y = total_seeds['Number'].max()*1.05
# Loop through all prairie types except the last one (remnant)
for i in range(len(xlabs)-1):
# Only display significant results
if stars.loc['TP', xlabs[i]] != 'NS':
ax.text(i, max_y, stars.loc['TP', xlabs[i]], ha='center', va='bottom', fontsize=1.1*fs)
ax.axvline(2.5, c='gray', ls='dashed')
ax.set_facecolor('snow')
ax.set_yticks(range(0,10001,2500),range(0,10001,2500))
ax.set_xticks(range(len(xlabs)), xlabs, fontsize=fs)
ax.set_ylabel('Number of seeds', fontsize=fs)
fig.tight_layout()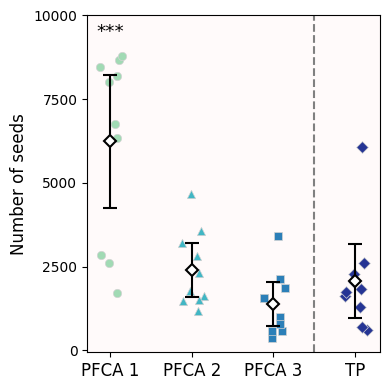
2.4 Non-parametric alternative: Conover with manual adjustments¶
Alternatively, we can compute Conover post hoc test without initial p-value adjustment (p_adjust = None).
conover = posthocs.posthoc_conover(total_seeds, val_col='Number', group_col='Plot', p_adjust=None)
conoverSince we only care about comparisons against Control (
TP), we will perform a BH procedure just on the p-values to such.
# The only three p-values we care for
pvals = conover.iloc[:-1, -1]
# Benjamini-Hochberg adjustment
# Put resulting p-value in a Series to keep track of where each pvalue comes from
pvals = pd.Series(stats.false_discovery_control(pvals), pvals.index)
pvalsPFCA 1 0.001297
PFCA 2 0.431797
PFCA 3 0.258996
dtype: float64Just like our original jitterplot + 95% Confidence Intervals suggested, only young restored prairies report a different seed rain compared to remnant prairies (p-value < 0.05). As these prairies age, their seed rainfall is comparable to the primeval prairies (p-value > 0.05).
Congratulations, you’re done!¶
Submit this assignment by uploading it to the course Canvas web page. Go to the “Pre-class assignments” folder, find the appropriate submission folder link, and upload it there.
See you in class!
© Copyright 2026, Division of Plant Science & Technology—University of Missouri
- Kettenbach, J. A., Miller‐Struttmann, N., Moffett, Z., & Galen, C. (2017). How shrub encroachment under climate change could threaten pollination services for alpine wildflowers: A case study using the alpine skypilot,Polemonium viscosum. Ecology and Evolution, 7(17), 6963–6971. 10.1002/ece3.3272
- Wynne, K. C., Parker‐Smith, M. J., Murdock, E. M., & Sullivan, L. L. (2024). Quantifying seed rain patterns in a remnant and a chronosequence of restored tallgrass prairies in north central Missouri. Journal of Applied Ecology, 61(12), 3017–3027. 10.1111/1365-2664.14806