Bootstrap and confidence intervals: urban birds and seed rains¶

Credits: PBS
Learning goals of today’s assignment¶
Recap how to use bootstrap to compute confidence intervals whenever a formula is not immediately available
Use SciPy to do bootstrap confidence intervals under the hood
Assignment instructions¶
Work with your group to complete this assignment. Instructions for submitting this assignment are at the end of the Notebook. The assignment is due at the end of class.
Importing the modules that we will need¶
Before we start anything, it is good practice to have all our imports as the first Python cell
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from scipy import stats
from sklearn import metrics1. Predicting bird diversity in urban settings¶
(This is the same text as in Homework 04)
There is a wealth of satellite data out there. With it, we can compare large swaths of land and environments at once, which can improve our biodiversity predictions. The normalized difference vegetation index (NDVI)—a widely used index captured by satellite cameras to determine “plant green-ness”—often shows positive relationships with bird diversity. However, its reliability as a predictor across contrasting urban contexts remains uncertain.
You will examine the relationships between the NDVI and bird species richness across three cities—Columbia MO (USA), Xalapa (Mexico), and MedellÃn (Colombia)—using Landsat-8 satellite imagery with buffer distances of 200m. Think of “camera focus settings” if you’re unfamiliar with buffer distances.
All the data is taken from:
MacGregor-Fors, I, Garizábal-Carmona, JA, García-Arroyo, M, Fishel, E, Nilon, CH, Lemoine-Rodríguez, R (2026) Does NDVI explain patterns of urban bird diversity? Insights from temperate to tropical cities. Urban Forestry & Urban Greening 116: 129211.
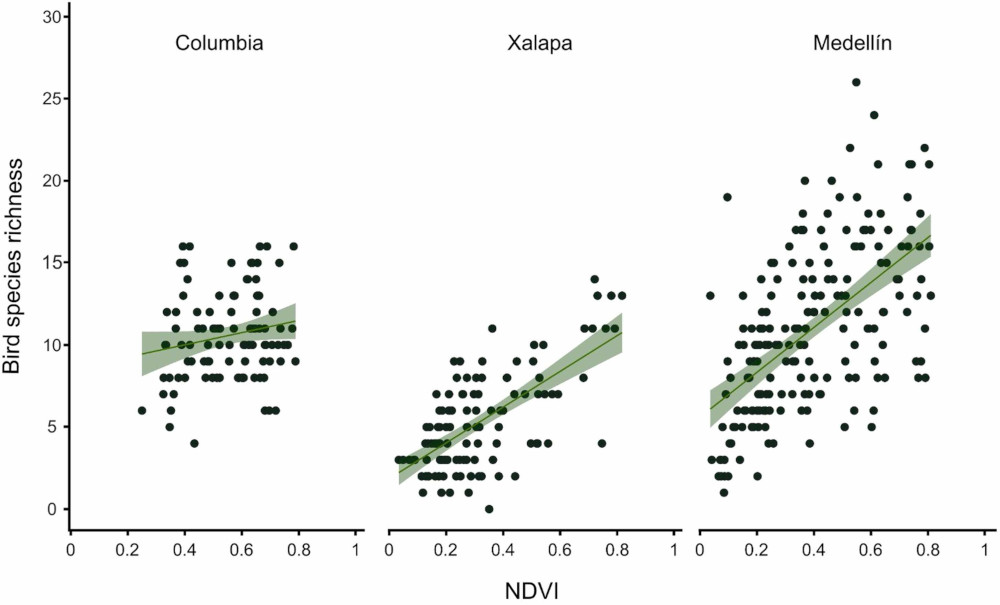
Credits: MacGregor-Fors et al (2026)
✅ Question 1
In your own words, what information do you get out of this figure?
✎ Put your answer here
1.1 Data loading and wrangling (2pt)¶
✅ Task 2
Load the
'Bird_Richness_NDVI_Woody_Pages7-20.xlsx'file (attached in Canvas). Notice that it is an Excel file, not a CSV.Display the first few rows to make sure it looks good. It should be 405 rows and 15 columns long.
# Load with pandasThings to keep in mind: Each row represents a different geographical Point:
City: The city where the data comes from.
BR: Bird-richness index: the higher means larger diversity of birds species.
L8: NDVI data from the Landsat-8 satellite.
For both satellites, we have 4 buffer distances (camera resolutions): 50m, 100m, 200m, and 400m.
✅ Task 2 (continued)
Mask and make a subDataFrame looking only at the data from Columbia.
We will work with this subdataframe from hereafter
# Your subdataframe1.2 Correlations¶
Let’s check if bird richness in Columbia is correlated to NDVI according to Landsat-8 data with 200 meters buffer distance.
✅ Task 3
Make a scatter plot of NDVI versus bird richness.
Remember to add x- and y-axes labels.
# Complete the scatterplot
fig, ax = plt.subplots(1,1, figsize=(3,4), sharex=True, sharey=True)
# Color the background ever so slightly
ax.set_facecolor('snow')
# Uncomment and complete
#ax.scatter( ... ) 
✅ Question 4
From the scatter plot alone, do you think NDVI is a good predictor of bird richness in Columbia?
✎ Put your answer here.
✅ Task 5
Now compute and print both the Pearson and Spearman correlation coefficients along their respective p-values.
# Your code✅ Question 6
Are Pearson and Spearman coefficients quite different or quite similar?
What conclusion do you draw by looking at both of them? Does it match your intuition from Q4?
✎ Put your answer here.
1.3 Confidence intervals for Pearson’s correlation: the PearsonRResult object¶
Confidence intervals are not limited to means: we can also compute confidence intervals for the Pearson’s . Its interpretation is the same as the CI for means:
Pearson’s 95% confidence interval is an interval that will contain the true Pearson’s 95% of the times.
Said other way: if we were to repeat our experiment 100 times, the 95% CI contains the at least 95 times.
The formula to compute a Pearson’s confidence interval is quite complicated, though This is because, unlike a normal distribution, Pearson’s can never go outside the range.
The good news is that SciPy already does all the math for us with stats.pearsonr. Check the Returns section of stats.pearsonr.
# You've already done this multiple times
pearsonr = stats.pearsonr( x_variable, y_variable )
print(pearsonr)
# But we can also get a confidence interval by doing
ci = pearsonr.confidence_interval(confidence_level = 0.95)
print(ci.low, ci.high)
# It does 95% CI by default✅ Task 7
Compute and print the Pearson’s correlation 95% confidence interval for the NDVI versus bird richness data above.
Also print the 99% CI.
# Your code✅ Question 8
Do the confidence inteval values change or reinforce your hypothesis from Q4?
If you were a consultant for Columbia’s bird conservancy group, would you advise them to invest in NDVI data collection and analysis?
✎ Put your answer here.
1.4 Confidence intervals for Spearman’s correlation: bootstrapping¶
But what about Spearman’s coefficient? We have two bad news.
stats.spearmanrdoes not return an object that can compute confidence intervals for us. At least not up to SciPy 1.18.The math behind Spearman’s confidence intervals is even more exotic.
But we have one good news: we can bootstrap. Recall the steps:
Generate a new samples from our original measurements by sampling with replacement
In this case, we consider a
(ndvi_value, br_value)pair as a single point.
Compute and save the Spearman’s coefficient
Repeat steps 1-2 a lot of times (like )
Get the and quantiles of all the Spearman’s coefficients
✅ Task 9
The tricky part is to bootstrap a pair of measurements instead of a single one, as we did back in Day 19. A strategy is to sample (with replacement) a set of indices instead. Then we use those indices to get both NDVI and BR values.
Use the
rng.integersfunction to generate a random array of integers between 0 and<length of NDVI data>. It must havesizeof<length of NDVI data>.Save such array of random numbers as a
random_indicesvariable.Use the array to get the corresponding NDVI and BR values
For example, you might want to do
ndvi[random_indices]ifndviis an arrayOr
ndvi.iloc[random_indices]if it is a Series
Compute the Spearman’s correlation coefficient with your new sampled values
# Your code
rng = np.random.default_rng(42)✅ Task 10
Now put things on a loop:
Make an array with
np.zerosof lengthN = 1000where you’ll save Spearman coefficients.In a loop:
Make a new random set of indices like in T9
With the indices, get a sample of NDVI values and their corresponding BR values
Compute and save the spearman correlation
Repeat times
# Your code
N = 1000✅ Task 11
Now use
np.quantileto get and print the quantiles corresponding to the 95% confidence interval ().Print the 99% CI as well.
Remember that these are the and quantiles.
# Your code✅ Question 12
Do the confidence inteval values make sense?
How do they compare to the CIs from Pearson? Is this like in Q6?
✎ Put your answer here.
2. Seed rainfall in Northern Missouri praires [Time-permitting]¶
(This is the same text from Homework 04)
Let’s switch gears. For this part, the research quantifies patterns of seed rain—the process of seeds falling from plants to the soil—in a remnant tallgrass prairie and various stages of restored prairies. It reveals that young prairies produce significantly more seed rain than previously understood. The study found distinct changes in seed rain metrics as prairies aged, with the oldest restorations showing comparable quantities to the remnant prairie, but lacking in species composition. The findings suggest that increasing seeding rates of desirable species may be necessary to enhance restoration outcomes.
More details and data on:
Wynne, KC, Parker-Smith, MJ, Murdock, EM, & Sullivan, LL (2024) Quantifying seed rain patterns in a remnant and a chronosequence of restored tallgrass prairies in north central Missouri. Journal of Applied Ecology, 61: 3017–3027
The goal is to reproduce Figure 1b:
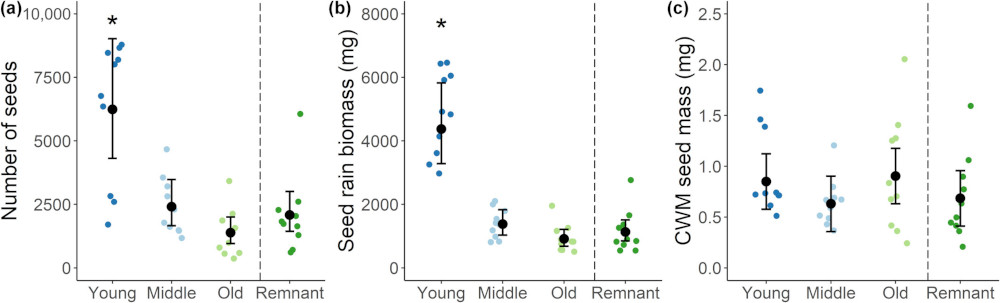
Credits: Wynne et al (2024)
✅ Question 13: Just looking a Figure 1b
What is reflected on the x-axis?
What is reflected on the y-axis?
In your own words, what information do you get out of this figure?
✎ Put your answer here
2.1 Data loading¶
✅ Task 14
Load the
'Seed_Rain_Traits_Dataset.csv'file (attached in Canvas). Notice that it is an Excel file, not a CSV.Display the first few rows to make sure it looks good. It should be 4275 rows and 8 columns long.
# Your codeImportant columns and information:
Plot: Prairie type
PFCA 1 = Young-aged restored prairie
PFCA 2 = Middle-aged restored prairie
PFCA 3 = Old-aged restored prairie
TP = remnant prairie in 2019
Transect: Corresponding transect number at a site (10 per site).
Number: The number of seeds collected from traps.
TotWeight: Total seed rain biomass (mg)
✅ Task 15
With your original DataFrame, group the rows by prairie age (
Plot) and transectCompute the total biomass of seeds for each prairie age–transect combination. Remember pandas has a
.sumfunction.Use the
as_index=Falseparameter to obtain a DataFrame instead of a Series.The first five rows should read something like:
| Plot | Transect | TotWeight | |
|---|---|---|---|
| 0 | PFCA 1 | 1 | 2973.886640 |
| 1 | PFCA 1 | 2 | 4920.950468 |
| 2 | PFCA 1 | 3 | 6435.186945 |
| 3 | PFCA 1 | 4 | 4836.356308 |
| 4 | PFCA 1 | 5 | 6052.586332 |
# Your code✅ Task 16
Peform three t-tests to check if the seed counts from restored prairies (PFCA 1, PFCA 2, PFCA 3 for young, middle aged, and old, respectively) are different compared to remnant prairies (TP).
Mask your DataFrame from Task 15 appropriately
Print your t-test results
# Your tests✅ Question 17
Based on your results above, what do you think is the relationship—if any—between prairie restoration age and seed counts?
✎ Put your answer here
✅ Task 18
But the p-values alone might not tell the full picture. Now make a jitterplot to confirm or reject your thoughts. Before that, make a summary of your summary.
Make a new DataFrame that is a summary of the one in T15: you want the seed biomass mean, SE, and sample size for each prairie age
Group rows by
PlotGet the seed biomass mean, SE, and sample size (
count) for each ageDisplay your new summary
# Your code here✅ Task 19
Use the values in your T18 DataFrame and append to it two new columns with the lower and upper 95% confidence intervals of the mean.
Remember to set
as_index = False
# Your code
alpha = 0.95✅ Task 20
Like Figure 1(b), make a jitterplot where different columns correspond to different restoration ages
Uncomment and edit the lines to plot the mean biomass along the 95% CI like in Wynne et al (2024)
Remember that the indices of your summary-summary DataFrame (from T19) are conveniently
0, 1, 2, 3Label the x- and y-axes
# Your plot
fs = 12
rng = np.random.default_rng(42)
nudge = rng.uniform(-0.15, .15, 10000)
# for i in range(len(<summary dataframe>)):
#ax.scatter([i], [summary.loc[i, 'mean']], c='k', s=75, zorder=2)
#ax.plot([i,i], [summary.loc[i, 'low_ci'], summary.loc[i, 'high_ci']], c='k', marker='_', ms=10)✅ Question 21
Does the visualization match your thoughts from Q17?
If you were a consultant for a conservancy NGO, what would you tell them about waiting times to see some true restoration taking place?
✎ Put your answer here
Congratulations, you’re done!¶
Submit this assignment by uploading it to the course Canvas web page. Go to the “In-class assignments” folder, find the appropriate submission link, and upload it there.
See you next class!
© Copyright 2026, Division of Plant Science & Technology—University of Missouri
- MacGregor-Fors, I., Garizábal-Carmona, J. A., García-Arroyo, M., Fishel, E., Nilon, C. H., & Lemoine-Rodríguez, R. (2026). Does NDVI explain patterns of urban bird diversity? Insights from temperate to tropical cities. Urban Forestry & Urban Greening, 116, 129211. 10.1016/j.ufug.2025.129211
- Wynne, K. C., Parker‐Smith, M. J., Murdock, E. M., & Sullivan, L. L. (2024). Quantifying seed rain patterns in a remnant and a chronosequence of restored tallgrass prairies in north central Missouri. Journal of Applied Ecology, 61(12), 3017–3027. 10.1111/1365-2664.14806