D is for dictionaries and dinosaurs¶

Credits: smbc-comics.com
Learning goals for today’s assignment¶
Practice storing data into dictionaries and looping through it
Load data using NumPy so that you can visualize it using matplotlib
Work with NumPy “array” objects to compute simple statistics using built-in NumPy functions.
Use NumPy and matplotlib to look for correlation in data
Assignment instructions¶
Work with your group to complete this assignment. Instructions for submitting this assignment are at the end of the Notebook. The assignment is due at the end of class.
Background: Allometry, revisited¶
In this Notebook we will keep exploring the power of allometry (pun not intended). In the last assignment, we set to model body weight based solely on the femur’s circumference based on an allometric relationship:
¶
for some constant values . If you recall from College Algebra, the formula above corresponds to a line.
The data for this assignment was adapted from:
Campione, N.E., Evans, D.C. (2012) A universal scaling relationship between body mass and proximal limb bone dimensions in quadrupedal terrestrial tetrapods. BMC Biol 10(60).
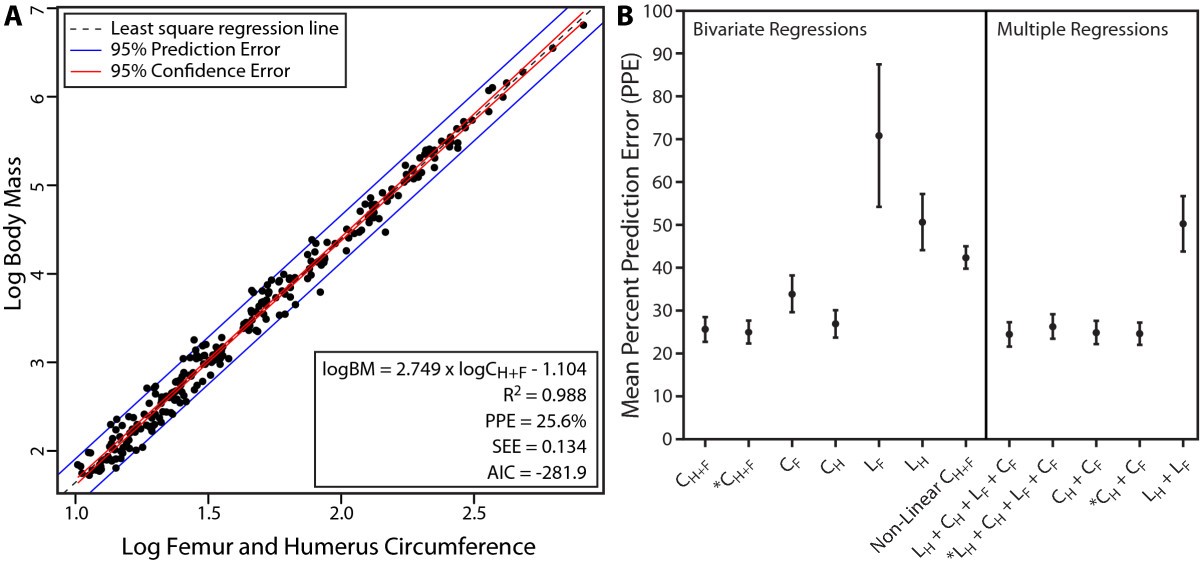
Credits: Campione and Evans (2012)
✅ Question: Only looking at Figure A
What information can you extract from the graph above?
Do you think it is sensible to assume (Body Mass) and (Femur Circumference) follow a linear relationship, like the formula above suggests?
How can we use the above information to predict the body mass of dinosaurs?
✎ Put your response here
1. Load tigers and hamsters with NumPy and dictionaries¶
# Although there are some exceptions, it is generally a good idea to keep all of your
# imports in one place so that you can easily manage them. Doing so also makes it easy
# to copy all of them at once and paste them into a new notebook you are starting.
# Bring in NumPy and Matplotlib
import numpy as np
import matplotlib.pyplot as pltTo use this notebook for your in-class assignment, you will need these files:
bovidae.csv(buffalo-like)canidae.csv(dog-like)cricetidae.csv(hamster-like)felidae.csv(cat-like)mustelidae.csv(badger-like)sciuridae.csv(squirrel-like)
In the pre-class you already saw a small sample of this kind of data: each file has some animals of the same family and measurements related to their body mass (in grams), and femur bones (in mm).
Take a moment to look at the contents of these files with an editor on your computer. For example,
*.csvfiles open with Excel or, even better, look at it with a simple text editor like NotePad or TextEdit or just try opening it inside your Jupyter Notebook interface.
As you saw in the pre-class assignment, you can use the command below to load in the body mass and femur circumference data.
# use NumPy to read data from a csv file
family = 'bovidae'
buff_mass, buff_femur = np.loadtxt(family + '.csv', usecols = [1,5], unpack=True, delimiter=',', skiprows=1)Once you have your data, it is always a good idea to look at some of it to be sure it is what you think it is. You could use a print statement, or just type the variable name in an empty cell.
buff_femurarray([ 69. , 67.25, 47.55, 167.5 , 122. , 156.5 , 58.95, 88. ,
52.65, 87. , 100. , 57.8 , 92.5 , 111. , 79. , 81.5 ,
46. , 97. , 62. , 135. ])✅ Question 1
What do you think this data represents?
✎ Put your answer here
1.1 Using dictionaries (from the pre-class)¶
| Container Type | Mutable or Immutable | Initialization Without Values | Initializtion With Values | Adding Values to Container | Removing Values from Container | Modifying Values | Access Method | Notable Operations and Additional Information |
|---|---|---|---|---|---|---|---|---|
| Dictionary | Mutable |
| d={'Hordeum':'vulgare'} |
| del d['Hordeum'] #removes the entry related to Horedeum. If there is not such an element, this will cause an error | d['Juglans'] = 'nigra' # Now we get 'Juglans' associated to species 'nigra' instead of 'regia' | Access by key: d['Hordeum'] # if there is no key named 'Hordeum', it will cause an error 1 | See webpage at here for some helpful methods when dealing with dictionaries. |
Remember that you can loop through all the values in the dictionary by doing
for key in dictionary:
# do something with the value dictionary[key]Now we need to load the data for the other five families. You could copy/paste and edit the loadtxt function above five more times. But this would mean a lot of copy/paste down the road if you want to compute statistics or make plots. Instead, we will load the data as entries of two large dictionaries.
✅ Task 2
Below is a list families with the names of the six families to be analyzed. Note that the strings in this list match the filenames of the databases for today. Except they are missing the .csv extension.
Initialize an empty
massdictionary where you’ll eventually put mass data.Initialize an empty
femurdictionary where you’ll eventually put femur data.Loop through the
familieslistInside the loop, load the mass and femur values from the CSV of the corresponding family.
You might need to add the
.csvextension to the string. How do you concatenate strings?Add the mass data in the
massdictionary. Use the family name (fromfamilies) as its key.Same for the
femurdictionary
The femur dictionary should look like
{'bovidae': array([ 69. , 67.25, 47.55, 167.5 , 122. , 156.5 , 58.95, 88. ,
52.65, 87. , 100. , 57.8 , 92.5 , 111. , 79. , 81.5 ,
46. , 97. , 62. , 135. ]),
'canidae': array([24.85, 40.6 , 51.75, 44.15, 25.75, 27.15, 23.3 , 26.95, 16.25]),
'cricetidae': array([ 7.15, 8. , 5.6 , 8.2 , 11. , 5.6 , 5.7 , 6.75, 11.8 ,
11.05, 8. , 9.85, 7.5 , 7. , 10. , 10. ]),
'felidae': array([ 67.5 , 30. , 42. , 40.85, 39. , 38.25, 41.4 , 109. ,
72.5 , 61. , 102.5 , 90.5 , 63. , 62.5 ]),
'mustelidae': array([29.3 , 35. , 24.4 , 24.5 , 22.05, 7.7 , 10.2 , 13.05, 12.5 ,
14.7 , 27.75]),
'sciuridae': array([13.5 , 10.25, 25.1 , 22. , 14.6 , 18.25, 10.05, 12. , 8.7 ,
10.9 , 8.8 , 6. , 5.95, 9.95])}# Read in data from the remaining files.
# Store the values in two dictionaries---mass and femur
# The dictionary keys help us keep track of which data is from which family
families = ['bovidae', 'canidae', 'cricetidae', 'felidae', 'mustelidae', 'sciuridae']
# initialize empty dictionaries mass and femur
# loop through each of the families above:
# load the mass and femur data corresponding to the right filename
# store the mass and femur data in the right dictionary with the right key
# print the femur dictionary to makes sure it looks like it should✅ Question 3
Before you move on, what is the variable type of the
femurvariable you’ve just made?What about of
femur['bovidae']?
Use the type() function to check. Does this match your expectations?
✎ Put your answer here
2. Descriptive statistics of data sets¶
Now that you have read in the data, use NumPy’s statistics operations from the pre-class to compare various properties of the body masses of the extant quadrupeds.
mean
median
standard deviation
2.1 Means and Medians¶
What is the mean of a data set?
The mean, also referred to as the average–represented by the Greek letter mu ()–is calculated by adding up all of the observations in a data set, and dividing by the number of observations in the data set.
The mean of a data set is useful because it provides a single number to describe a dataset that can be very large. However, the mean is sensitive to outliers (observations that are far from the mean), so it is best suited for data sets where the observations are close together.
What is the median of a data set?
The median of a data set is the middle value of a data set, or the value that divides the data set into two halves. The median also requires the data to be sorted from least to greatest. If the number of observations is odd, then the median is the middle value of the data set. If the number of observations is even, then the median is the average of the two middle numbers.
Unlike the mean, because the median is the midpoint of a data set, it is not strongly affected by a small number of outliers.
2.2 Using NumPy to Calculate Mean and Median¶
We can write a function to calculate the mean and median ourselves, but NumPy already did that work for us! The documentation for np.mean shows additional options, but the basic use is:
np.mean(data)Similarly, the median is calculated by:
np.median(data)✅ Task 4
In the cell below, calculate and print the mean and median of the body mass for each of the animal families, alongside the family name.
Because all our data is in a dictionary with keys in
families, we can simply loop through thefamilieslist to access the mass data for each animal family.
Remember masses are in grams. Do the means and medians make intuitive sense?
# Put your code here
# Loop through the mass dictionary (every entry is an array of values):
# compute the mean and median mass
# print the family name alongside the mean and median2.3 Calculating Standard Deviation¶
One way to describe how “spread out” a data set is, we look at its standard deviation—often represented with the Greek letter sigma ().
where the symbols in this equation represent the following:
: Mean
: Number of observations
: the value of dataset at position
Note: In most of the textbooks you’ll find instead of . Doing corrects the sampling bias. This is known as the Bessel’s correction. We’ll discuss more about it later in the semester.
Similarly to np.mean() and np.median(), we can calculate the standard deviation with NumPy:
# The ddof argument forces NumPy to divide 1/N-1 instead of 1/N
np.std(data, ddof=1)✅ Task 5
In the cell below, calculate and print the standard deviation of body mass for each of the families. Use code similar to Task 4.
Which family reports the largest SD? The smallest? Which family/families have an SD larger than its mean?
Are there any results you find surprising?
# put your code here2.4 Visualizing the Data with matplotlib¶
Let’s have a better idea of what’s in the files.
✅ Task 6
For the Bovidae family:
Compute the log (base 10) of the body mass and the femur circumference
If you store these log values in a variable prior to plotting them, make sure they are in another dictionary.
Do a scatterplot of log body mass versus log bone circumference using
matplotlib.This means that log body mass should go on the y-axis and log bone circumference should go on the x-axis.
This is our first example of doing some (very simple!) data science - looking at some real data. As a reminder, the data came from an actual research paper. If you ever find data like this in the real world, you could build a Notebook like this one to examine it. In fact, your projects at the end of the semester might be much larger versions of this.
# Do a scatterplot mass vs femur circumference here
fig, ax = plt.subplots(figsize=(5,3))
Without labels, plots are not very useful. If you showed them to someone else they would have no idea what is in them. In fact, if you looked at them next week, you wouldn’t remember what is in them. Let’s use a little more matplotlib to make them of professional quality.
There are two things that every plot should have: labels on each axis. And, there are many other options:
✅ Task 7
Now let’s make a single plot containing all the families at once
For every family, make a scatterplot like in Task 6 in the same plot; Also add a legend.
Give each family a different color and marker using the
colorsandmarkerslists.You might want to have
edgecolor='black'as part of yourax.plotarguments to give each marker a black contour for easier visualization.Hint: Remember your work from Pre-Class 09 and that we can loop with indices.
If you find yourself waiting for help from an instructor, you can also try using duckduckgo to answer your questions. Searching the internet for coding tips and tricks is a very common practice!
The Python community also provides helpful resources: they have created a comprehensive gallery of just about any plot you can think of with an example and the code that goes with it. That gallery is here and you should be able to find many examples of how to make your plots look professional. (You just might want to bookmark that webpage...)
# Make another plot here with all the data in the same plot and include a legend
colors = ['r', 'yellow', 'dodgerblue', 'orange', 'gray', 'cyan']
markers = ['o', '^', 'v', 's', 'D', 'p']
fig, ax = plt.subplots(figsize=(7,4))
# Loop through all family names:
# log 10 mass values for family i
# log 10 femur values for family i
# scatterplot of mass vs femur; make sure colors and markers are different for every family; add a family label
# add grids, titles, legends, and axes labels
✅ Question 8
What observations about the data do you have?
Does it look like the log observations follow a line?
What do you think of the fact that both hamsters and buffalos seem to follow the same trend despite huge size differences?
✎ In the data I see....
Part 3: Looking for correlations in data (Time Permitting)¶
In the plot above (and in the original paper) you probably observed that log body mass and log bone circumference follow a nice linear pattern. This suggests that both measurements are correlated.
We are going to explore how to quantify these correlations. There are many ways to measure correlation, but we are going to use the Pearson Correlation Coefficient (also referred to as “r”, “rho”, “”, or “correlation coefficient”). The Pearson Correlation Coefficient ranges from -1 to 1 and provides a measure of how dependent on one another your variables are.
If the correlation coefficient is close to 1 or -1, then the correlation is strong, if it is close to zero, the correlation is weak. If the the correlation coefficient is negative, then the y values decrease as x increases. If the correlation coefficient is positive, then the y values increase as x increases. See the image below for a visualization of this!
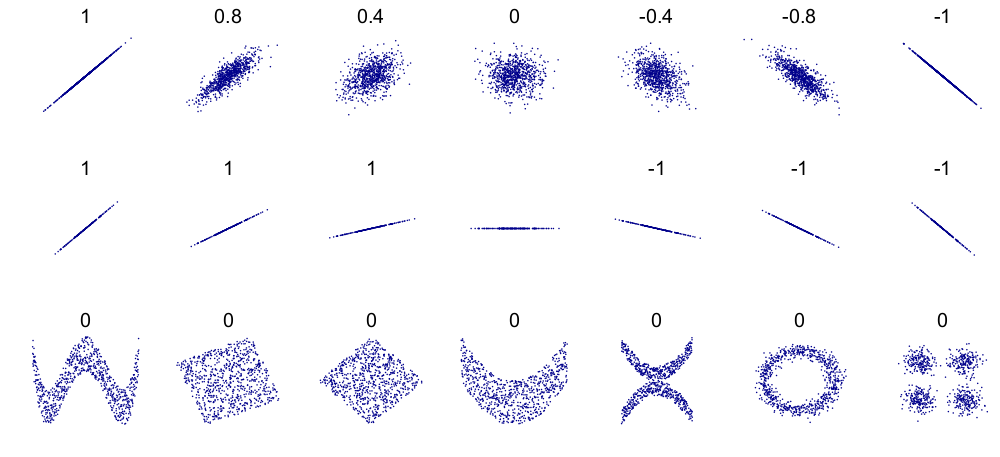
Credits: Wikipedia
.
3.1 Using np.corrcoef()¶
To calculate the correlation coefficient, we are going to use another NumPy function, np.corrcoef. For two measurments x and y, you can use it like
np.corrcoef(x,y)It will return all of the possible correlation coefficients (including the data with itself) as an array.
✅ Task 9
Pick two families of your choice.
In the cell below, calculate the correlation coefficient between log body mass and the log femur circumferences for these two families.
Were there any differences between your qualitative observations and your quantitative calculations?
# put your code here
✎ I observed.....
## ASIDE: Saving Plots¶
Finally, you will need to use your plots for something. In your other classes and labs you often will need to make plots for your assignments and lab reports - now is the time to start using Python for that! Modify the code above to write the plot into a file in PNG format. You just need to add the following lines at the end of the cell where you make plots. Here are a couple of examples for how you can save files as a PNG file:
fig.savefig('my_plot.png', dpi=150, bbox_inches='tight')
# You can also have .jpg, .pdf, or .svg files
# Increase or decrease dpi for better or worse resolutionPut your name in the filename so that we can keep track of your work.
Congratulations, you’re done!¶
Submit this assignment by uploading it to the course Canvas web page. Go to the “Pre-class assignments” folder, find the appropriate submission folder link, and upload it there.
See you in class!
© Copyright 2026, Division of Plant Science & Technology—University of Missouri
- Campione, N. E., & Evans, D. C. (2012). A universal scaling relationship between body mass and proximal limb bone dimensions in quadrupedal terrestrial tetrapods. BMC Biology, 10(1). 10.1186/1741-7007-10-60